


VAIL Use Case: Verifiable Evals
How can you prove a model passed an eval with the reported score?

Josh: Numbers don’t lie.
Joey: They lie all the time.The West Wing (Season 2): “The War at Home”
After spending several months of computation and many millions of dollars to train a new model, the primary way model builders announce it to the world is by touting how well the new model performs on popular benchmarks. For example, on April 18, 2024, Meta announced Llama 3, the latest foundation model and successor to Llama 2. Here is what Meta shared regarding the model’s performance:
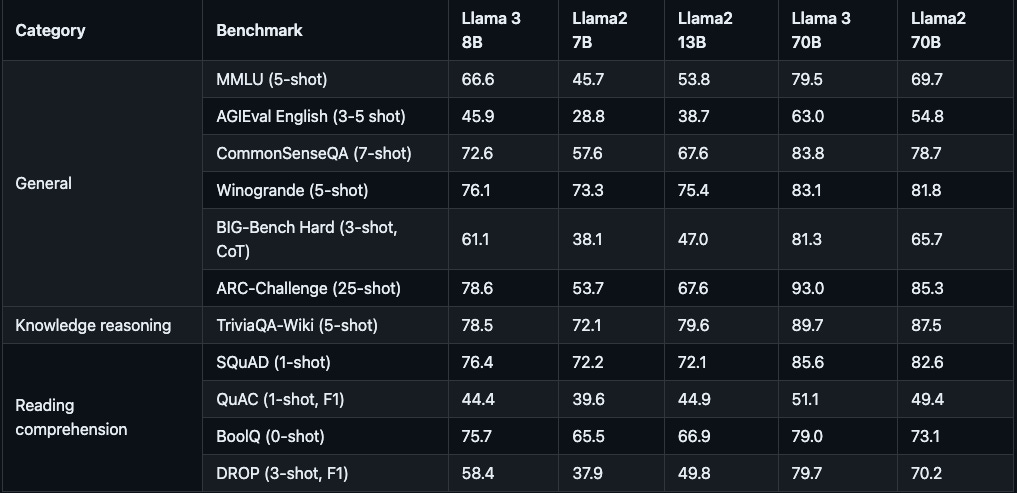
Additionally, the announcement showcases its performance and superiority to other comparable models (on the same benchmarks): Google’s Gemini, Anthropic’s Claude 3 Sonnet, and Mistral’s Mistral 7B.
Benchmark evaluations are meant to provide an apples-to-apples comparison of different AI models, to showcase how they each perform on the same datasets. How precise is the model? How satisfactory is the model’s outputs relative to a human’s? How does the model perform across a variety of information domains?
Without a doubt, having common benchmarks is an important tool to help end-users and enterprises evaluate which models to use and build on top of.
However, how can an end-user or enterprise know the model indeed performs as stated on the relevant benchmark?
What is a benchmark? How does it work?
When we talk about benchmarks like MMLU or MedQA, we are really talking about a curated evaluation dataset of queries and correct responses. For example sets of questions & answers for a chat-based model, like this one from MedQA:
{
"question": "A 67-year-old man with transitional cell carcinoma of the bladder comes to the physician because of a 2-day history of ringing sensation in his ear. He received this first course of neoadjuvant chemotherapy 1 week ago. Pure tone audiometry shows a sensorineural hearing loss of 45 dB. The expected beneficial effect of the drug that caused this patient's symptoms is most likely due to which of the following actions?",
"answer": "Cross-linking of DNA",
"options": {
"A": "Inhibition of thymidine synthesis",
"B": "Inhibition of proteasome",
"C": "Hyperstabilization of microtubules",
"D": "Generation of free radicals",
"E": "Cross-linking of DNA"
},
"meta_info": "step1",
"answer_idx": "E"
}After training a model (an LLM in this case), the model is then presented with the questions in the evaluation dataset - think of each question as a prompt to the model. The model is asked to choose an answer by selecting one of the options given. The answers are compared with what is known to be the correct answer. A score is calculated based on the number of correct and incorrect responses given by the model (eg. the sum of the correct answers divided by the total of questions asked).
This score is what gets posted publicly on leaderboards, model cards, and other marketing materials touting the model’s capabilities.
Is honesty the best policy?
The limitations of benchmarks, evaluations, and audits (or lack thereof) is discussed in internal circles but rarely openly. The current regime of sharing results on common benchmarks serves everyone. Closed source models get to tout their models’ capabilities and make statements about how we are ever closer to AGI. Open source models get to show how close they are to the closed source counterparts…like younger brothers boasting their skills relative to their older brothers.
Benchmarks are the primary means to convince developers, end-users, enterprise customers to use your model instead of any of the others. There is literally billions of dollars on the table. Unfortunately, this creates a very strong motive to “juke the stats.”
I’m not suggesting anyone has done this, and I couldn’t prove it if I did suspect it. Which is another incentive to be dishonest about your numbers, it is very hard, if not impossible to tell.
How Do You Know?
When reading a press release about a new model and its scores on different evals, it’s tough to know if the model actually performs as well as stated. For an end-user (without a GPU cluster handy), its impossible to re-run the evaluations and confirm the results.
Leaderboards are a step up. Thankfully groups like Huggingface and Artificial Analysis are running evaluation suites on their own hardware to post results of different models on different evaluation sets. However, it is still difficult (if not impossible) to know if the model was trained specifically to perform well on the leaderboard. Otherwise known as overfitting the training to the test which reduces effectiveness on new, unseen data.
Building & running evaluations is not a common practice because building proper evaluations is HARD. If you’re a large enterprise, you will most likely outsource evaluations to a third party or worse to the model builders themselves. How can you trust to results from the evaluators?
Scale has recently announced a way to evaluate models without risk of the data getting leaked into the model at training. This is awesome, but will quickly become a bottleneck as Scale won’t be able to evaluate every model available.
Verifiable Evaluations
As the number of models grows exponentially, our ability to evaluate these models goes to zero which also makes evaluating ever more critical.

(Llama 3 release April 18, 2024, 1k+ variants publicly available after 3 days. 12,450 as of June 19, 2024…64 days from release)
Enter verifiable evaluations.
With verifiable evaluations, model developers provide verifiable proof that the model performs as stated on relevant evaluations. When a new model is shared, anyone can verify that the model was evaluated with the benchmarks stated.
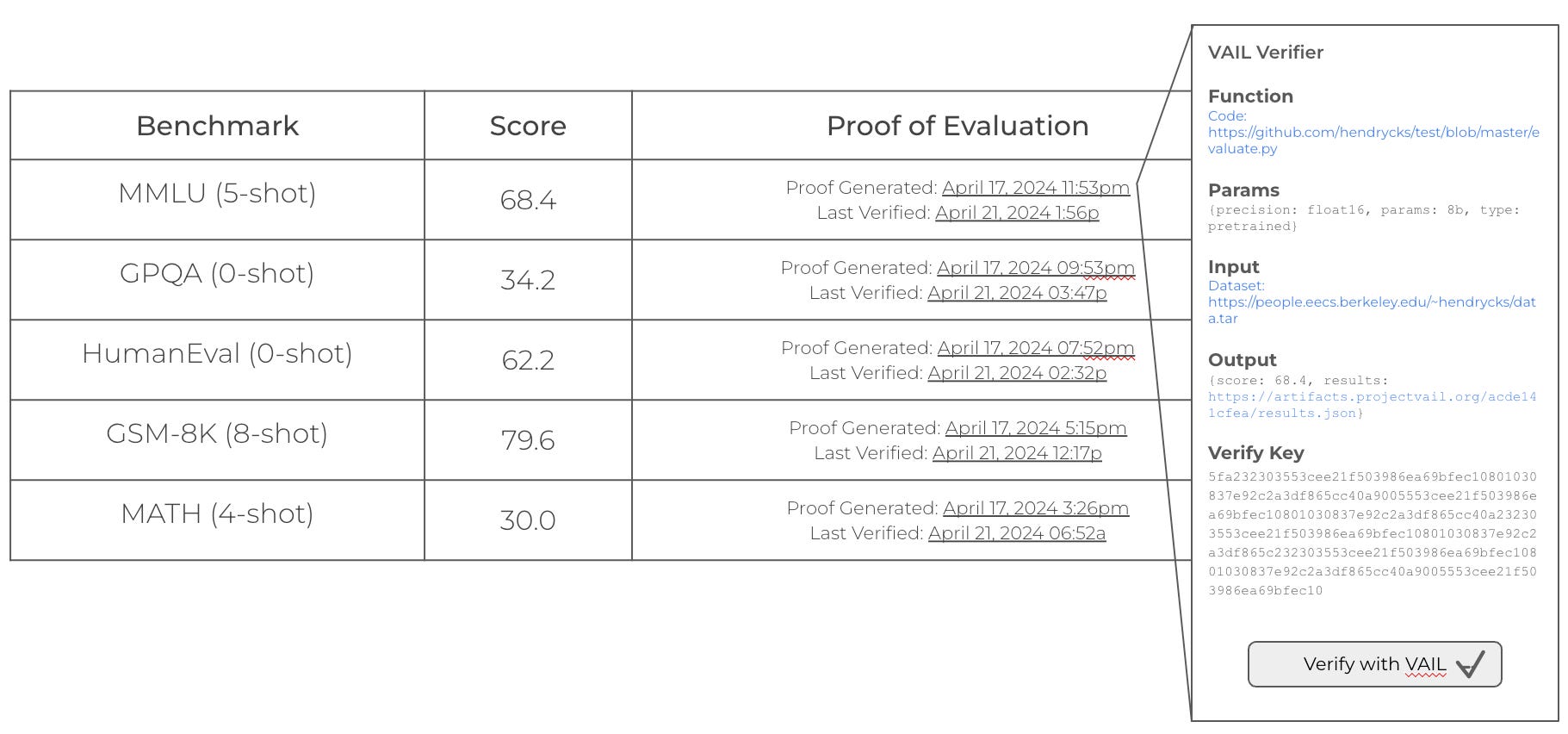
Evaluation tools (like this one or this one) are basically just running a sample of prompts through a model and comparing its output to the known correct answers. With verifiable computation, a proof would be generated that this evaluation tool was run with this specific model, these inputs, and generated these outputs.
If the evaluation tool was changed, it would break the proof.
If a different model was used, it would break the proof.
If the inputs were altered, it would break the proof.
If the outputs were changed after the fact, it would break the proof.
In a proof, the prover solves a complex math equation and gives the verifier specific values to plug into a formula. If the formula checks out, the verifier knows the prover solved the equation correctly, without seeing the actual solution.
A proof is essentially the values to plug into a math equation - the equation is the computation that someone wants to prove only they can solve (like an evaluation of an AI model). So verifying a proof is plugging in the values given by the prover into the math equation and checking the results. This is cheap and fast. It does not require a GPU cluster or a large quantity of data. Yay math!
Furthermore, anyone that’s interested could also verify the proof for themselves. Model builders don’t need to re-run evaluations so long as the models and inputs are not changed. The cherry on top is that model builders do not have to share the secret parts of the model, like the weights. Those can remain private! Yay math again!
When the model changes (eg. weights) or the inputs change, that would require generating new results and thus a new proof.
Our belief is that verifiable computation will be an important primitive in the future of AI-powered software systems. Developing and running evaluations is hard work and resource intensive. More so if everyone has to do it for themselves. Verifiable evaluations can help and provide a layer of assurance for AI models that will end up inside the software we use for all kinds of important, daily tasks.