


The Need for Public Goods Infrastructure for AI
What is it and why it matters as we embrace a world of many, many models.

Cooperation, Interoperability, and Resiliency
Ideal public infrastructure is a system that can and will be used by most people. The utility of such a system is so broad and pervasive that we all shift our behavior around that infrastructure. For example, we shift our behavior around the transportation system by choosing to live within or around freeways, metro trains, and airports. It shapes our lives. And, you can choose to opt out of using the system, but it will be much more difficult to work with others.
The internet is another example of public infrastructure. Our world and our daily lives are shaped by the internet, in more ways than we think about on a conscious level.
Cooperation and interoperability among entities within a public infrastructure is is necessary to serve a vast array of needs. These entities include those providing services and those consuming services. When different entities can work together, freely exchange information, and enhance each other’s capabilities, things work better and costs generally go down for everyone. Another crucial aspect of public infrastructure is the need for resiliency. As people come to depend on it, it needs to be available and resilient to outages and different kinds of attacks that would weaken or alter the utility of the infrastructure. Imagine how hard things get when your internet connection goes down or when a freeway is closed.
Public Infrastructure for AI
AI is heading in the direction of impacting everyone’s lives, whether they know it yet or not. Every software-based system (and even physical systems like manufacturing facilities or cars) will be improved, rewritten, or created by AI. Because this will impact broad swaths of the population and how we function as a society, we will need to approach the rollout of AI like we would public infrastructure.
For AI, as the number of different models (rapidly) proliferates, the need for cooperation, interoperability, and resiliency grows. When we see more models developing different capabilities and specializations (text summarization, video generation, domain-specific data analysis & reasoning), it is only natural that multiple models will be working together. Even the largest state of the art models are “outsourcing” tasks to other, smaller models for performance. The larger model is used for reasoning, refining, and curating the results to present to the end users.
Cooperation
AI Models will need to develop a way to communicate with each other and likely with models developed by external organizations. One could imagine a SOTA model like GPT4 calling out to a Mistral or Llama-based model that is fine-tuned for a specific task. Mistral or Llama could also recursively call out to others as well.
When web applications were proliferating, this cooperation between systems happened via APIs, or structured, programmatic interfaces. A developer would write code specific to each API for both the input and the output.
Currently, language models (LLMs) communicate using natural language (english predominantly) which is fortunate for our observability of the LLM’s behavior. This is very different than highly structured interfaces we’ve had in the past like RESTful APIs. We can more easily observe these interactions and see if the models are cooperating in a healthy/productive manner. Eventually, the models may develop their own shorthand for communicating or move to a language that is incoherent or unobservable to human monitors. Even today, you can embed whole sets of knowledge into a model using vector embeddings which is just a set of weights trained around a corpus of data. This removes the observability of how two models are interacting with each other.
Interoperability
Interoperability is also an unsolved problem. How does a model find and select the right model to outsource special tasks too? Is a model limited to just a handful of other models, hardcoded by the model developers (or the developers’ employer)? Should there be a DNS-like system to enable the discovery of special-purpose models for a given task? Will there be a page-rank like system to assign rank and authority for each available model so its easier to know which is the best-fit for the given task? Can you only select models trained within a geographic area (eg. US only models)? Will there be hardware-based decisions to find the best model but also available on the most efficient hardware?
We have yet to truly explore and address problems related to interoperability of AI models. The race is currently on to build larger, monolithic, general pupose models that obviate the need to work with other models. This will be short lived since even the most advanced models will cost way too much to train and run for any one organization.
Resiliency
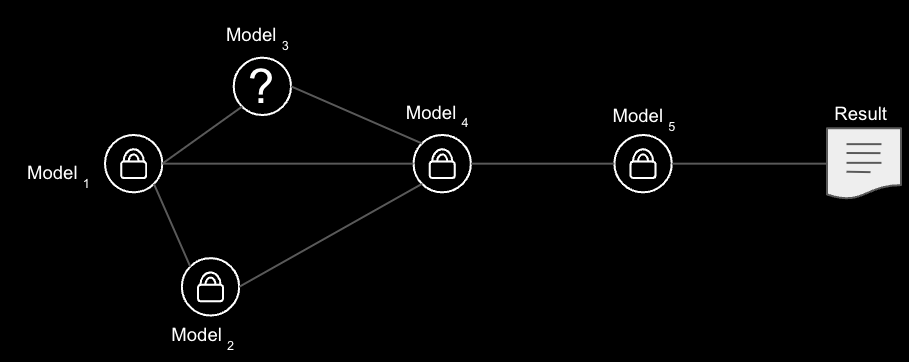
Another unsolved problem relates to resiliency. If there is a network of models employed to complete a multistep task, how does the end-user ensure that a malicious model was not selected to complete a task? That one malicious model could alter the results and possibly even corrupt the other models in future tasks if they are retrained with the corrupted results. Reinforcement learning, whether by human feedback or via synthetic data is a common method employed to improve models for future queries and tasks. The quality of the feedback will dramatically effect future performance. This is amplified when a malicious model can steer outputs, every so subtly, towards the malicious actors’ intentions instead of the end-users’. Additionally, when you have multiple models working to complete a task, a common practice is to chain or stack prompts together (eg. using system prompts on top of end-user prompts). Prompt injection already been shown to weaken the models and any security or alignment filters in place. Furthermore, if you include retrieval augmented generation (RAG), the originating prompt can be obfuscated from the end-user after multiple “priming” prompts for the model.
Conclusion
There is a lot we can gain from a system that employs many different models to complete tasks. We can benefit from the expertise of many different teams, datasets, and training methods to get the best result for a given task. Currently (in early 2024) we are racing to develop large, capable, general models. And we are racing to gather enough computing resources and data to train these models to ultimately use them for real world tasks. However, we need to start thinking about the shared, public infrastructure that enables the work of all the disparate teams to bind together and provide a larger, more valuable system. Just like the Internet and it’s underlying protocols, we can create something that is valuable beyond just a few silo’d networks.
A goal for VAIL is to define an open standard and protocol that would setup a transparent way for models to interact with each other without trading off resiliency. This will enable us to use AI for high value use cases that we otherwise wouldn’t trust AI with. There is a debate to be had about whether we’d make better decisions with AI than without. However, throughout history, we’ve always done better when information and tools spread widely and worked together (hammers need nails and vice versa). That’s how humans have been able to improve for centuries. Why would AI be any different?